Business Objects universes are stored in the RDBMS, but in both cases, the cubes are stored externally. Cognos has its own server or desktop based PowerCubes, while Business Objects microcubes are part of a document, which can again be server based or local. These look the same regardless of which database they were sourced from, so the same tools can be used with any database (one of their strengths compared to tools from Oracle, Microsoft or IBM which are database-specific).
As for Oracle OLAP products, the long-established OFA and OSA are still based on Express, which also uses cubes based outside the Oracle database.Oracle9i OLAP Option AW does have cubes and dimensions hosted inside the database, but most Oracle products don't yet build or support such cubes and nor do most third party products (except as vanilla SQL queries).
Friday, February 22, 2008
Wednesday, February 20, 2008
Wednesday, February 13, 2008
How do you test your database?
This is a very generic question. I will be describing my generic database testing method as well as stored procedure testing methods.
Testing Databases:
· Table Column data type and data value validation.
· Index implementation and performance improvement.
· Constraints and Rules should be validated for data integrity.
· Application field length and type should match the corresponding database field.
· Database objects like stored procedures, triggers, functions should be tested using different kind of input values and checking the expected output variables.
Testing Stored Procedures:
· Understand the requirements in terms of Business Logic.
· Check that code follows all the coding standards.
· Comparing the fields' requirements of application to the fields retrieved by a stored procedure. They should match.
· Repeatedly run stored procedures many times with different input parameters and compare the output with expected results.
· Pass invalid input parameters and see if a stored procedure has good error handling.
Sunday, February 10, 2008
Thursday, February 7, 2008
Find and remove duplicate rows from a table
One of the most important features of Oracle is the ability to detect and remove duplicate rows from a table. While many Oracle DBA place primary key referential integrity constraints on a table, many shops do not use RI because they need the flexibility.
The most effective way to detect duplicate rows is to join the table against itself as shown below.
SELECT
BOOK_UNIQUE_ID,
PAGE_SEQ_NBR,
IMAGE_KEY
FROM
page_image A
WHERE
rowid >
(SELECT min(rowid) FROM page_image B
WHERE
B.key1 = A.key1
and
B.key2 = A.key2
and
B.key3 = A.key3
);
Please note that you must specify all of the columns that make the row a duplicate in the SQL where clause. Once you have detected the duplicate rows, you may modify the SQL statement to remove the duplicates as shown below:
DELETE FROM
table_name A
WHERE
A.rowid >
ANY (SELECT B.rowid
FROM
table_name B
WHERE
A.col1 = B.col1
AND
A.col2 = B.col2
);
You can also detect and delete duplicate rows using Oracle analytic functions:
delete from
customer
where rowid in
(select rowid from
(select
rowid,
row_number()
over
(partition by custnbr order by custnbr) dup
from customer)
where dup > 1);
Simple syntax to delete duplicate rows from a table
DELETE FROM our_table
WHERE rowid not in
(SELECT MIN(rowid)
FROM our_table
GROUP BY column1, column2, column3... );
Tuesday, February 5, 2008
Overview of Web intelligence
Web Intelligence is designed to help organizations increase trust in decision making by providing
an intuitive, yet powerful, ad hoc query interface for business users and analysts, as well as
interactive viewing and analysis for casual users. With BusinessObjects XI Release 2, Web
Intelligence will introduce powerful new capabilities, making it easier for end users to access,analyze, and share information.
These features include:
1). The ability to access data from multiple universes and synchronize it within a single report (also known as synchronized multiple data providers)
2). The ability to create custom queries including sub queries, combined queries, and edit SQL
3). Support for the vast majority of the full-client formula language functions
4). Report creation features such as data ranking and custom sorts
BusinessObjects full-client capabilities that will be available with
Desktop Intelligence, but not available with Web Intelligence XI Release 2
include:
1). XML or visual basic data providers.
2). Specific power-user query capabilities designed for production reporting requirements.
3). The creation of queries built on the results of other queries.
4). Stored procedures (often used to group a set of SQL statements used in a query). (Note that organizations are now using the derived tables inherent in modern database systems to meet the same needs more efficiently).
5). Some specialized users of the BusinessObjects full-client generate queries using free-hand SQL. (Note that while this is not supported in Web Intelligence XI Release 2, it will be possible to edit existing SQL.) Many organizations are transferring the burden of custom SQL to the derived table method mentioned above. This ensures these specialized results areavailable for all users, and not confined to a single report
an intuitive, yet powerful, ad hoc query interface for business users and analysts, as well as
interactive viewing and analysis for casual users. With BusinessObjects XI Release 2, Web
Intelligence will introduce powerful new capabilities, making it easier for end users to access,analyze, and share information.
These features include:
1). The ability to access data from multiple universes and synchronize it within a single report (also known as synchronized multiple data providers)
2). The ability to create custom queries including sub queries, combined queries, and edit SQL
3). Support for the vast majority of the full-client formula language functions
4). Report creation features such as data ranking and custom sorts
BusinessObjects full-client capabilities that will be available with
Desktop Intelligence, but not available with Web Intelligence XI Release 2
include:
1). XML or visual basic data providers.
2). Specific power-user query capabilities designed for production reporting requirements.
3). The creation of queries built on the results of other queries.
4). Stored procedures (often used to group a set of SQL statements used in a query). (Note that organizations are now using the derived tables inherent in modern database systems to meet the same needs more efficiently).
5). Some specialized users of the BusinessObjects full-client generate queries using free-hand SQL. (Note that while this is not supported in Web Intelligence XI Release 2, it will be possible to edit existing SQL.) Many organizations are transferring the burden of custom SQL to the derived table method mentioned above. This ensures these specialized results areavailable for all users, and not confined to a single report
Sunday, February 3, 2008
Displaying Row numbers in a Business objects report
Steps to add Row number to business objects report:
1). Create a variable with the following formula:
=runningCount(any variable)
2). Add the Variable to the table as the first column.
Steps to reset the row numbers:
1). Add a second argument to the runningCount function:
=runningCount( ; )
when the value of the reset variable changes , the row count will reset to 0
1). Create a variable with the following formula:
=runningCount(any variable
2). Add the Variable to the table as the first column.
Steps to reset the row numbers:
1). Add a second argument to the runningCount function:
=runningCount(
when the value of the reset variable changes , the row count will reset to 0
Data Warehousing Objects - Fact Table, Dimension Table, Hierarcy Table
Data Warehousing Objects
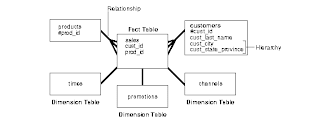
Fact tables and dimension tables are the two types of objects commonly used in dimensional data warehouse schemas.
Fact tables are the large tables in your warehouse schema that store business measurements. Fact tables typically contain facts and foreign keys to the dimension tables. Fact tables represent data, usually numeric and additive, that can be analyzed and examined. Examples include sales, cost, and profit.
Dimension tables, also known as lookup or reference tables, contain the relatively static data in the warehouse. Dimension tables store the information you normally use to contain queries. Dimension tables are usually textual and descriptive and you can use them as the row headers of the result set. Examples are customers or products.
Fact Tables
A fact table typically has two types of columns: those that contain numeric facts (often called measurements), and those that are foreign keys to dimension tables. A fact table contains either detail-level facts or facts that have been aggregated. Fact tables that contain aggregated facts are often called summary tables. A fact table usually contains facts with the same level of aggregation. Though most facts are additive, they can also be semi-additive or non-additive. Additive facts can be aggregated by simple arithmetical addition. A common example of this is sales. Non-additive facts cannot be added at all. An example of this is averages. Semi-additive facts can be aggregated along some of the dimensions and not along others. An example of this is inventory levels, where you cannot tell what a level means simply by looking at it.
Creating a New Fact Table
You must define a fact table for each star schema. From a modeling standpoint, the primary key of the fact table is usually a composite key that is made up of all of its foreign keys.
Dimension Tables
A dimension is a structure, often composed of one or more hierarchies, that categorizes data. Dimensional attributes help to describe the dimensional value. They are normally descriptive, textual values. Several distinct dimensions, combined with facts, enable you to answer business questions. Commonly used dimensions are customers, products, and time.
Dimension data is typically collected at the lowest level of detail and then aggregated into higher level totals that are more useful for analysis. These natural rollups or aggregations within a dimension table are called hierarchies.
The lookup table provides the detailed information about the attributes. For example, the lookup table for the Quarter attribute would include a list of all of the quarters available in the data warehouse. Each row (each quarter) may have several fields, one for the unique ID that identifies the quarter, and one or more additional fields that specifies how that particular quarter is represented on a report (for example, first quarter of 2001 may be represented as "Q1 2001" or "2001 Q1").
A dimensional model includes fact tables and lookup tables. Fact tables connect to one or more lookup tables, but fact tables do not have direct relationships to one another. Dimensions and hierarchies are represented by lookup tables. Attributes are the non-key columns in the lookup tables.
Hierarchies
Hierarchies are logical structures that use ordered levels as a means of organizing data. A hierarchy can be used to define data aggregation. For example, in a time dimension, a hierarchy might aggregate data from the month level to the quarter level to the year level. A hierarchy can also be used to define a navigational drill path and to establish a family structure.
Within a hierarchy, each level is logically connected to the levels above and below it. Data values at lower levels aggregate into the data values at higher levels. A dimension can be composed of more than one hierarchy. For example, in the product dimension, there might be two hierarchies--one for product categories and one for product suppliers.
Dimension hierarchies also group levels from general to granular. Query tools use hierarchies to enable you to drill down into your data to view different levels of granularity. This is one of the key benefits of a data warehouse.
When designing hierarchies, you must consider the relationships in business structures. For example, a divisional multilevel sales organization.
Hierarchies impose a family structure on dimension values. For a particular level value, a value at the next higher level is its parent, and values at the next lower level are its children. These familial relationships enable analysts to access data quickly.
Below figure illustrates a common example of a sales fact table and dimension tables customers, products, promotions, times, and channels.

Saturday, February 2, 2008
Overview of Chasm and Fan traps (BusinessObjects Universe)
Relational databases can return incorrect results due to limitations in the way that joins are performed in relational databases. Unlike loops, which return fewer rows, the Chasm and the Fan traps are two common circumstances which return too many rows. You can use Designer to resolve both types of problems in your universe schema.
Chasm trap
The Chasm trap occurs when two “many to one” joins converge on a single table. For example a customer can place many orders/and or place many loans.
Fan trap
The Fan trap occurs when a “one to many” join links a table which is in turn linked by another “one to many” join.
For example when you run a query that asks for the total orders by each order line, for a particular customer, an incorrect result is returned as you are performing an aggregate function on the table at the “one” end of the join, while still joining to the “many” end.
Below is the Brief overview:
Chasm Trap:
A chasm occurs when a series of joins crosses a many >- one -< many relationship.
For example:
A >- B -< C
( Employees >-- Showroom --< Salary)
- Each showroom has many employees
- Each showroom has many annual salary figures
The number of employee records should not impact the total salary on the report.
If a query is written that spanned all three of those tables the data from table A and C, there would be duplicated and the measure values would be exaggerated. For example,
- X rows on the left
- Y rows on the right
- X * Y rows in the combined set
Solution 1:
Define a context for each table at the “many” end of the joins.
Context = Meaning
- A context is a sub-set of joins in a universe
- That sub-set of joins has a particular meaning
In our example you could define a context from A to B and from A to C. A context contains each join in the path. This creates two SQL statements and two separate tables in Business Objects, avoiding the creation of a Cartesian product. Using contexts is the most effective way to solve Chasm traps.
Solution 2:
Select the option ‘Multiple SQL Statements for Each Measure’ from the Universe Parameters dialog box in the tool. Only applies to measures. You force the SQL generation engine in Reporter to generate SQL queries for each measure that appears in the Query panel.
Fan Trap:
A fan trap occurs when joins “fan out” over multiple one -< many relationships in a row.
For example:
A -< B -< C (Ex: Customer --< Orders --< Order_Lines)
A fan trap is not quite as severe as a chasm trap. In fact there are many fan traps that can occur in a universe design that can be ignored as long as you control which types of objects you use.
There are two ways to solve a Fan trap problem.
• Using an alias and the aggregate awareness function. This is the most effective way to solve the Fan trap problem.
• Altering the SQL parameters for the universe. This only works for measure objects.
Both of these methods are described below.
Solution 1:
Aliases can resolve chasm traps
- Known as table aliases when writing SQL statements
- Used by BusinessObjects to logically separate the trap into pieces.
You create an alias table and use the aggregate awareness function. You cannot use this option if you have incompatible objects. You can do this as follows:
1. Create an alias for the table that is producing the multiplied aggregation.
2. Create a one to one join between the original table and the alias table.
3. Modify the select statement for the columns that are summed so that the columns in the alias table are summed and not the original table.
4. Apply the @AggregateAware function to the select statement. for example:
@AggregateAware(SUM(ORDERS.TOTAL_VALUE) , SUM(ORDERS_2.TOTAL_VALUE))
Solution 2:
- Create a separate SQL statement per aggregation.
- Aggregations on the same table require only 1 SQL statement.
You select the option ‘Multiple SQL Statements for Each Measure’. You force the SQL generation engine in Reporter to generate separate SQL queries for each measure that appears in the Query panel. You find this option on the SQL page of the Universe Parameters dialog box in the tool.
Chasm trap
The Chasm trap occurs when two “many to one” joins converge on a single table. For example a customer can place many orders/and or place many loans.
Fan trap
The Fan trap occurs when a “one to many” join links a table which is in turn linked by another “one to many” join.
For example when you run a query that asks for the total orders by each order line, for a particular customer, an incorrect result is returned as you are performing an aggregate function on the table at the “one” end of the join, while still joining to the “many” end.
Below is the Brief overview:
Chasm Trap:
A chasm occurs when a series of joins crosses a many >- one -< many relationship.
For example:
A >- B -< C
( Employees >-- Showroom --< Salary)
- Each showroom has many employees
- Each showroom has many annual salary figures
The number of employee records should not impact the total salary on the report.
If a query is written that spanned all three of those tables the data from table A and C, there would be duplicated and the measure values would be exaggerated. For example,
- X rows on the left
- Y rows on the right
- X * Y rows in the combined set
Solution 1:
Define a context for each table at the “many” end of the joins.
Context = Meaning
- A context is a sub-set of joins in a universe
- That sub-set of joins has a particular meaning
In our example you could define a context from A to B and from A to C. A context contains each join in the path. This creates two SQL statements and two separate tables in Business Objects, avoiding the creation of a Cartesian product. Using contexts is the most effective way to solve Chasm traps.
Solution 2:
Select the option ‘Multiple SQL Statements for Each Measure’ from the Universe Parameters dialog box in the tool. Only applies to measures. You force the SQL generation engine in Reporter to generate SQL queries for each measure that appears in the Query panel.
Fan Trap:
A fan trap occurs when joins “fan out” over multiple one -< many relationships in a row.
For example:
A -< B -< C (Ex: Customer --< Orders --< Order_Lines)
A fan trap is not quite as severe as a chasm trap. In fact there are many fan traps that can occur in a universe design that can be ignored as long as you control which types of objects you use.
There are two ways to solve a Fan trap problem.
• Using an alias and the aggregate awareness function. This is the most effective way to solve the Fan trap problem.
• Altering the SQL parameters for the universe. This only works for measure objects.
Both of these methods are described below.
Solution 1:
Aliases can resolve chasm traps
- Known as table aliases when writing SQL statements
- Used by BusinessObjects to logically separate the trap into pieces.
You create an alias table and use the aggregate awareness function. You cannot use this option if you have incompatible objects. You can do this as follows:
1. Create an alias for the table that is producing the multiplied aggregation.
2. Create a one to one join between the original table and the alias table.
3. Modify the select statement for the columns that are summed so that the columns in the alias table are summed and not the original table.
4. Apply the @AggregateAware function to the select statement. for example:
@AggregateAware(SUM(ORDERS.TOTAL_VALUE) , SUM(ORDERS_2.TOTAL_VALUE))
Solution 2:
- Create a separate SQL statement per aggregation.
- Aggregations on the same table require only 1 SQL statement.
You select the option ‘Multiple SQL Statements for Each Measure’. You force the SQL generation engine in Reporter to generate separate SQL queries for each measure that appears in the Query panel. You find this option on the SQL page of the Universe Parameters dialog box in the tool.
Overview of BusinessObjects CMS (Central Management Server)
The Central Management Server (CMS) is the key Component within Xi, handling security and the routing of requests to other services.
If the CMS is not running, then users will not be able to log into Business Objects.
The Central Management Server maintains a database of information that allows you to manage the BusinessObjects Enterprise Infrastructure.
The CMS has four main functions:
If the CMS is not running, then users will not be able to log into Business Objects.
The Central Management Server maintains a database of information that allows you to manage the BusinessObjects Enterprise Infrastructure.
The CMS has four main functions:
- Maintains security (users)
- Manages objects (folders, reports, and program objects)
- Manages servers (services)
- Manages auditing (system auditor).
Friday, February 1, 2008
Overview of Report Design
Report Design:
Guidelines & Best Practices:
Introduction:
Gives the basic guidelines/practices that could be followed in any Report Design.
General
--> Give meaningful names for the report tabs
--> For complex reports, keep an overview report tab explaining the report
--> Use the Report properties to give more information about the report
Dataproviders
--> Each Dataprovider should be given a name that reflects the usage of the data its going to fetch.
--> Select Objects in such a fashion that the resulting SQL gives a hierarchial order of Tables. This helps to achieve SQL Optimisation.
--> Avoid bringing lot of data into the report which will unnecessarily slow down the report performance.
Report Variables
--> Follow the naming convention of "var_" as prefix to each report level variable. This helps to identify Report Variables different from Universe Objects.
--> Each variable that carries a calculation involving division should have IF <> 0 THEN
Guidelines & Best Practices:
Introduction:
Gives the basic guidelines/practices that could be followed in any Report Design.
General
--> Give meaningful names for the report tabs
--> For complex reports, keep an overview report tab explaining the report
--> Use the Report properties to give more information about the report
Dataproviders
--> Each Dataprovider should be given a name that reflects the usage of the data its going to fetch.
--> Select Objects in such a fashion that the resulting SQL gives a hierarchial order of Tables. This helps to achieve SQL Optimisation.
--> Avoid bringing lot of data into the report which will unnecessarily slow down the report performance.
Report Variables
--> Follow the naming convention of "var_" as prefix to each report level variable. This helps to identify Report Variables different from Universe Objects.
--> Each variable that carries a calculation involving division should have IF
what is Designer and Creation Of Universe?
What is Designer?
Designer is a BusinessObjects IS module used by universe designers to create and maintain universes. Universes are the semantic layer that isolates end users from the technical issues of the database structure. Universe designers can distribute universes to end users by moving them as files through the file system, or by exporting them to the repository.
BO Universe is essentially a connection layer sitting between the source data and the DW. It is defined by the data mapping or schema or the relationship between database tables. Each universe is accessed by certain category of users. For example, finance people will access finance universe, sales people will access sales universe. The analogy is similar to a data mart.
The advantge of the BO universe is that if there are any changes in the source data structure, this change needs to be made only in the Universe and its effect gets pushed down to all the reports emanating from this universe. A good universe design helps is improving speed and contributes to the Best Practices using BO.
How do you design a universe?
The design method consists of two major phases.
During the first phase, you create the underlying database structure of your universe. This structure includes the tables and columns of a database and the joins by which they are linked. You may need to resolve loops which occur in the joins using aliases or contexts. You can conclude this phase by testing the integrity of the overall structure.
During the second phase, you can proceed to enhance the components of your universe. You can also prepare certain objects for multidimensional analysis. As with the first phase, you should test the integrity of your universe structure. Finally, you can distribute your universes to users by exporting them to the repository or via your file system.
Subscribe to:
Posts (Atom)


